Playwright로 Colab에서 연합뉴스 크롤링하기
Colab 노트북
231221_Playwright로 Colab에서 연합뉴스 크롤링하기.ipynb
Colaboratory notebook
colab.research.google.com
연합뉴스 최신기자 페이지(https://www.yna.co.kr/news/1)를 크롤링하는 코드를 짜달라는 요청이 들어왔다.아니 컴공 복전한 사람이 이런 것도 못해? 라고 힐난하고 책망하려던 차에...

---------------------------------------------------------------------------
SSLError Traceback (most recent call last)
/usr/local/lib/python3.10/dist-packages/urllib3/connectionpool.py in _make_request(self, conn, method, url, body, headers, retries, timeout, chunked, response_conn, preload_content, decode_content, enforce_content_length)
467 try:
--> 468 self._validate_conn(conn)
469 except (SocketTimeout, BaseSSLError) as e:
18 frames
SSLError: [SSL: UNSAFE_LEGACY_RENEGOTIATION_DISABLED] unsafe legacy renegotiation disabled (_ssl.c:1007)
During handling of the above exception, another exception occurred:
SSLError Traceback (most recent call last)
SSLError: [SSL: UNSAFE_LEGACY_RENEGOTIATION_DISABLED] unsafe legacy renegotiation disabled (_ssl.c:1007)
The above exception was the direct cause of the following exception:
MaxRetryError Traceback (most recent call last)
MaxRetryError: HTTPSConnectionPool(host='www.yna.co.kr', port=443): Max retries exceeded with url: /news/1 (Caused by SSLError(SSLError(1, '[SSL: UNSAFE_LEGACY_RENEGOTIATION_DISABLED] unsafe legacy renegotiation disabled (_ssl.c:1007)')))
During handling of the above exception, another exception occurred:
SSLError Traceback (most recent call last)
/usr/local/lib/python3.10/dist-packages/requests/adapters.py in send(self, request, stream, timeout, verify, cert, proxies)
515 if isinstance(e.reason, _SSLError):
516 # This branch is for urllib3 v1.22 and later.
--> 517 raise SSLError(e, request=request)
518
519 raise ConnectionError(e, request=request)
SSLError: HTTPSConnectionPool(host='www.yna.co.kr', port=443): Max retries exceeded with url: /news/1 (Caused by SSLError(SSLError(1, '[SSL: UNSAFE_LEGACY_RENEGOTIATION_DISABLED] unsafe legacy renegotiation disabled (_ssl.c:1007)')))위와 같은 에러를 만나버렸다. HTTPSConnectionPool(host='www.yna.co.kr', port=443): Max retries exceeded with url: /news/1 (Caused by SSLError(SSLError(1, '[SSL: UNSAFE_LEGACY_RENEGOTIATION_DISABLED] unsafe legacy renegotiation disabled (_ssl.c:1007)'))) 라는 에러로 쉽게 말해 SSL 인증을 할 수 없다, 이런 뜻이다.
이를 해결하기 위해서는 2가지 세팅이 필요한데, 먼저 적절한 Header 세팅이다. 크롤링은 일반적인 브라우저 요청과는 달라서, Header 쪽에 세팅이 좀 빈약하다. (주로 Cookie 혹은 User-agent) 그래서 이 쪽 세팅을 해줘야한다. Local에서 Jupyter Notebook으로 크롤링을 하는 경우에는 이 세팅만 적절히 해주면 requests가 잘 작동한다.
나머지 하나는 연합뉴스 홈페이지에서 사용하는 SSL 알고리즘에 맞는 방식으로 접근이 필요한데... Colab은 뭔가 버전이 안 맞아서 이게 안 된다. 즉, 리눅스 내부에 있는 OpenSSL을 통한 Requests 요청(curl과 유사)은 불가능하다.
그래서 Colab에서도 headless browser를 구동할 수 있는 playwright를 사용하기로 했다.
쉽게 말해 selenium처럼 browser를 구동하는 거라고 보면 되는데, 요새는 무슨 문제인지 colab에서 selenium이 잘 구동이 안되더라... 그래서 갈아탔다. + 여러 세팅이 더 쉽다.
설치
Installation | Playwright Python
Introduction
playwright.dev
!pip install pytest-playwright -q # 패키지 설치
!playwright install # 필요한 브라우저 설치playwright는 자체 install 기능을 통해 굳이 외부에서 필요한 브라우저를 찾기 않아도 알아서 다운로드 받아준다.
구동
Playwright | Playwright Python
Playwright module provides a method to launch a browser instance. The following is a typical example of using Playwright to drive automation:
playwright.dev
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch() # Chromium 브라우저 실행
page = await browser.new_page() # 새로운 웹 페이지 생성
await page.goto('https://www.yna.co.kr/news/1') # 지정한 URL로 이동
print(await page.title()) # 현재 페이지의 제목 출력
await browser.close() # 브라우저 종료
asyncio.run(main()) # 비동기 함수 실행공식 홈페이지의 예시 코드를 바탕으로, 연합뉴스 최신 기사 페이지의 제목(타이틀)을 출력하는 코드를 작성했다. 파이썬에서의 비동기 처리 (async-await)는 좀 어색하긴 하지만 JS(ECMAScript2016)의 경험이 있으므로 얼추 하고 넘어가려고 했는데...

---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-3-e86128b10562> in <cell line: 13>()
11 await browser.close()
12
---> 13 asyncio.run(main())
/usr/lib/python3.10/asyncio/runners.py in run(main, debug)
31 """
32 if events._get_running_loop() is not None:
---> 33 raise RuntimeError(
34 "asyncio.run() cannot be called from a running event loop")
35
RuntimeError: asyncio.run() cannot be called from a running event loop잘 되나 싶더니만 에러와 조우... (RuntimeError: asyncio.run() cannot be called from a running event loop)
다행히도 흔한 에러라서 바로 stackoverflow에서 해결책을 찾을 수 있었다. Colab에서는 nest_asyncio를 통한 추가 세팅이 필요했던 것!
Running Playwright on Google colab gives error : asyncio.run() cannot be called from a running event loop
I was trying to run playwright web automation on google colab but can't run the event loop on colab. This is what I tried !pip install playwright from playwright.sync_api import sync_playwright with
stackoverflow.com
import nest_asyncio
nest_asyncio.apply()
설정하고 구동하니까 잘 된다.
이것저것 섞어보자
!pip install pytest-playwright -q # 패키지 설치
!playwright install # 필요한 브라우저 설치
# 필요한 라이브러리 가져오기
from bs4 import BeautifulSoup # 웹 페이지 파싱을 위한 BeautifulSoup 라이브러리
import pandas as pd # 데이터 프레임을 생성하기 위한 Pandas 라이브러리
import asyncio # 비동기 작업을 위한 asyncio 라이브러리
from playwright.async_api import async_playwright # 웹 브라우징을 위한 Playwright 라이브러리
from google.colab import files # Google Colab에서 파일 다운로드를 위한 라이브러리
from datetime import datetime as dt # 현재 날짜 및 시간을 얻기 위한 datetime 라이브러리
from dateutil.relativedelta import relativedelta as rd # 날짜 연산을 위한 dateutil 라이브러리
import nest_asyncio # 비동기 작업 루프를 설정하기 위한 nest_asyncio 라이브러리
# 비동기 작업 루프 설정
nest_asyncio.apply()
# HTML 파싱을 위한 함수 정의
def parse_html(html):
soup = BeautifulSoup(html, 'lxml') # BeautifulSoup을 사용하여 HTML 파싱
return soup
# 현재 날짜 및 시간을 가져오는 함수 정의
def get_now():
now_dt = dt.utcnow() + rd(hours=9) # 현재 UTC 시간을 가져와서 9시간을 더해 한국 시간으로 변환
return now_dt.strftime('%Y-%m-%d_%H:%M:%S') # 날짜 및 시간을 문자열로 반환
# 데이터를 CSV 파일로 저장하는 함수 정의
def save_to_csv(tags):
items = tags.select('.section01 .item-box01') # HTML에서 뉴스 아이템 요소 선택
data = [{
'created_at': item.select_one('.txt-time').getText(), # 뉴스 작성 시간 가져오기
'title': item.select_one('.tit-news').getText(), # 뉴스 제목 가져오기
'lead': item.select_one('.lead').getText(), # 뉴스 요약 가져오기
'url': 'https:' + item.select_one('.tit-wrap')['href'], # 뉴스 URL 가져오기
} for item in items] # 모든 뉴스 아이템에 대한 정보를 리스트로 저장
df = pd.DataFrame(data) # 데이터를 Pandas 데이터 프레임으로 변환
fn = f'news_{get_now()}.csv' # 파일 이름 생성 (현재 시간 기반)
df.to_csv(fn) # 데이터 프레임을 CSV 파일로 저장
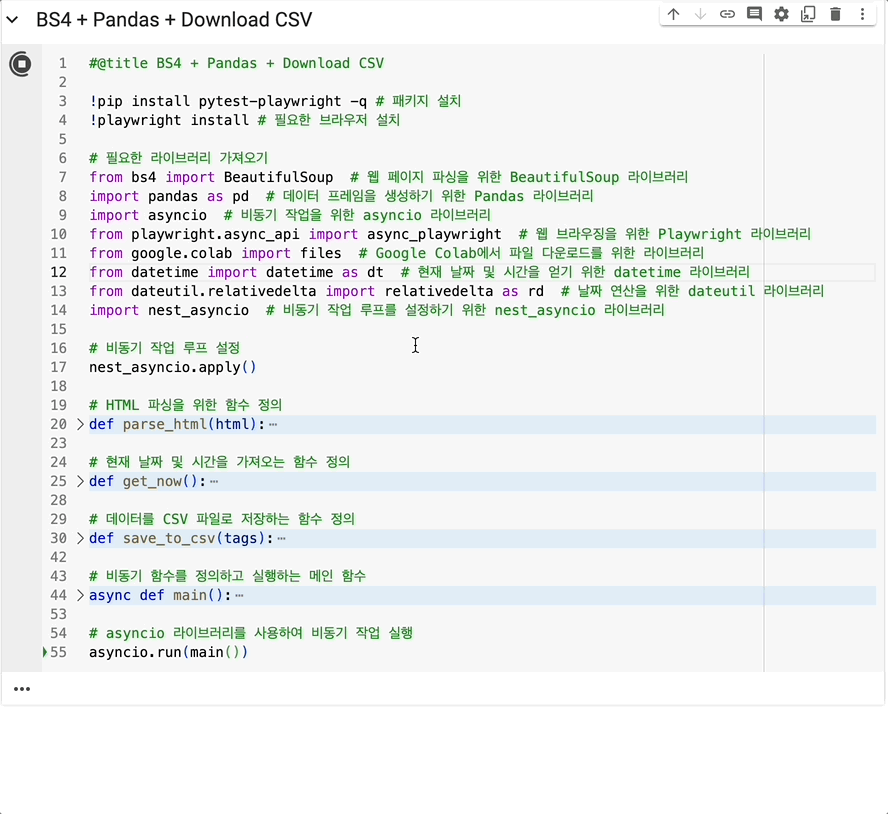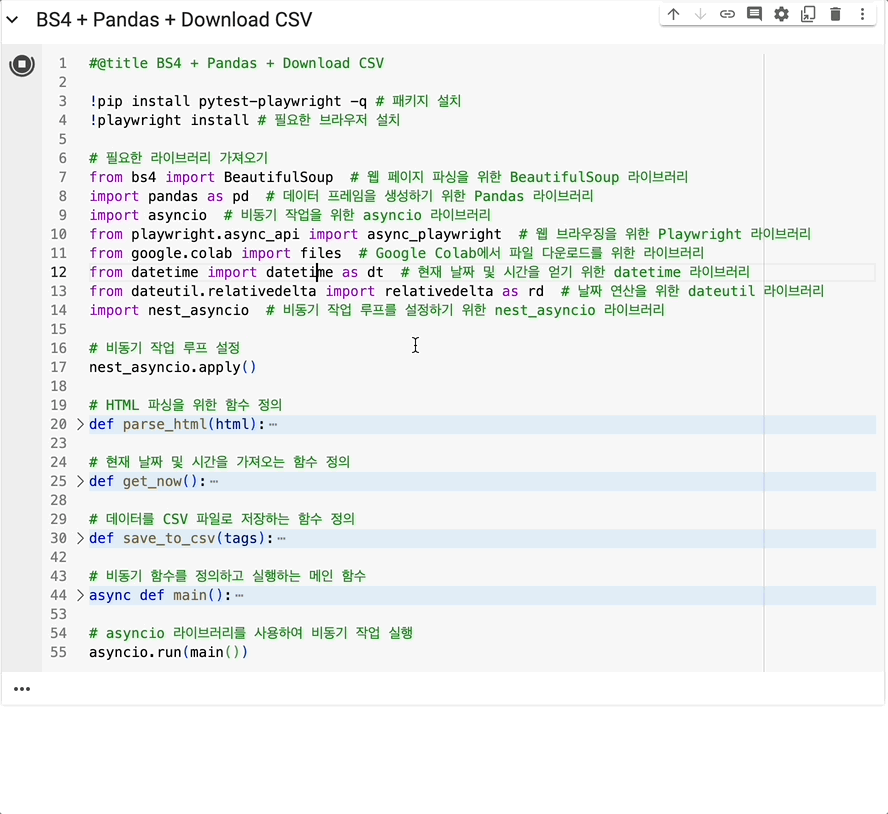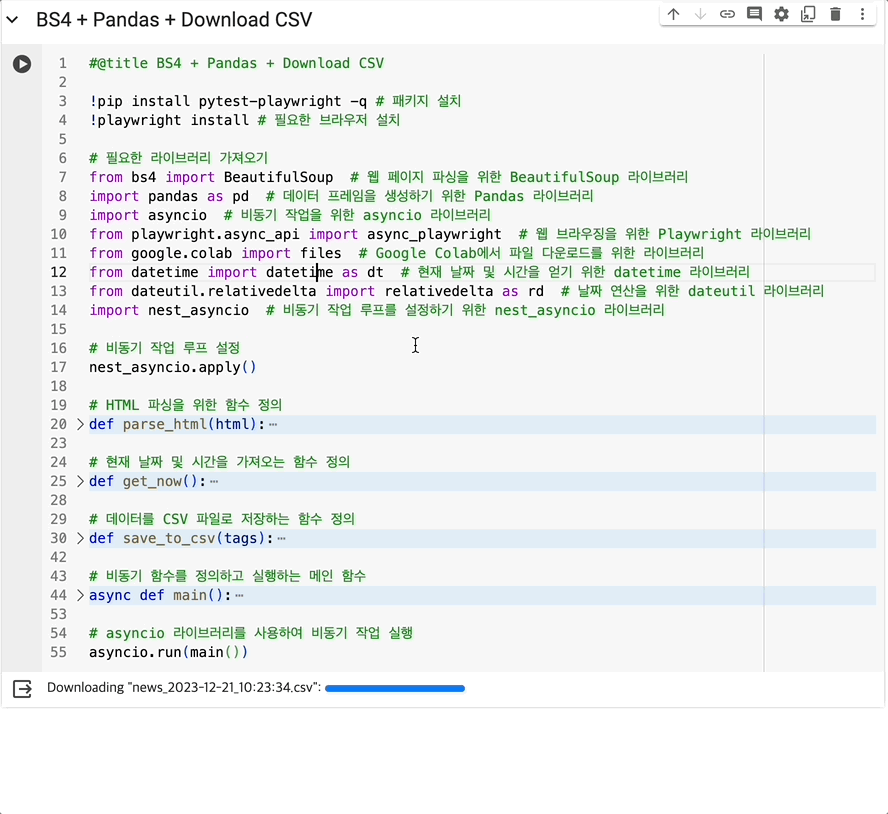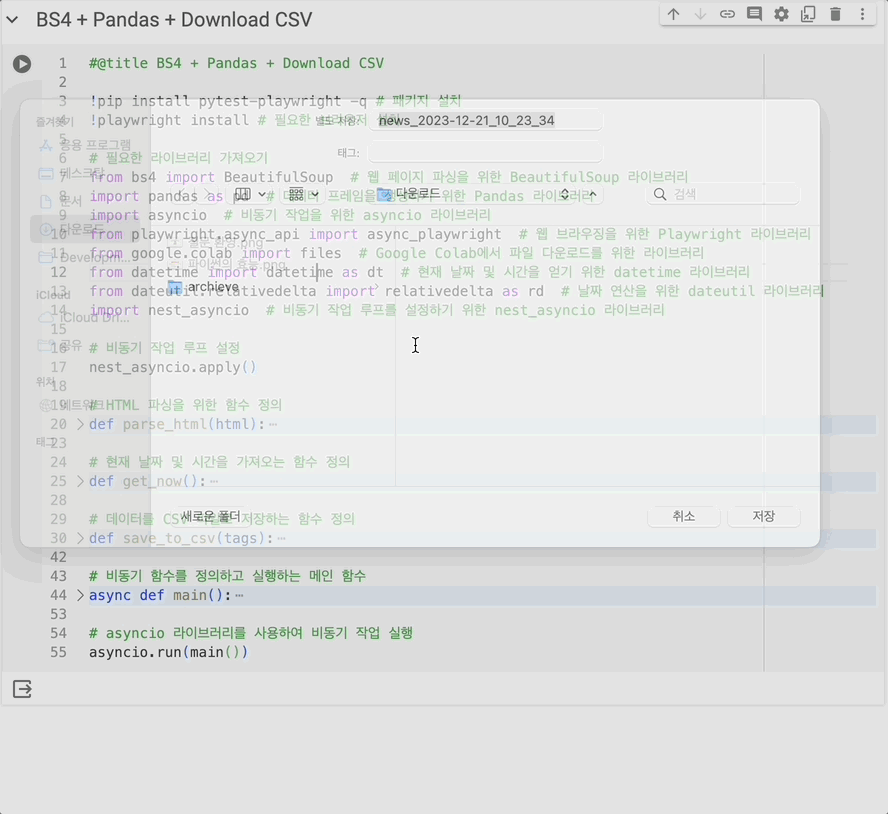
files.download(fn) # Google Colab에서 파일 다운로드
# 비동기 함수를 정의하고 실행하는 메인 함수
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch() # Chromium 브라우저 실행
page = await browser.new_page() # 새로운 웹 페이지 생성
URL = 'https://www.yna.co.kr/news/1' # 스크랩할 웹 페이지 URL
await page.goto(URL) # 웹 페이지로 이동
tags = parse_html(await page.inner_html('body')) # 웹 페이지의 HTML을 파싱
save_to_csv(tags) # 데이터를 CSV 파일로 저장
await browser.close() # 브라우저 종료
# asyncio 라이브러리를 사용하여 비동기 작업 실행
asyncio.run(main())뭐 어떻게든 데이터만 받아올 수 있으면 그 다음은 쉽다(?)
bs4를 통한 태그 파싱, pandas로 df 만들어서 저장, colab.files로 다운로드 진행 정도 버무려서 마무리.

'Today_I_Learned' 카테고리의 다른 글
| 펀드기준가격 스크레이핑을 위한 AWS 람다 함수(Node) (0) | 2024.08.13 |
|---|---|
| Shell로 BOJ VSCode Java 설정 자동화하기 (Mac 기준) (1) | 2024.01.17 |
| [Django DRF] Serializer에서 id를 사용한 M:N 관계 (0) | 2023.11.13 |
| AWS API Gateway로 DynamoDB PutItem 메서드 구현 (23.10.13) (1) | 2023.10.14 |
| multiprocessing를 통한 병렬 처리 파이썬 코드 예제 (0) | 2023.09.30 |